Improved site indexation by properly adjusted Robots meta tag
Note: Google has recently abolished Page Rank, that is why some information in this post may be out-of-date. Instead, we use own evaluation system – SB Rank, which is based on DA and PA index.
Proper management of your website is no less important than the quality and relevant content. Today we’ll consider one of the main optimization aspects for search engines – Robots meta tag optioning. Among all meta tags, Robots has a special importance, as it along with its attributes could help you to move up in search rankings. Yeah, you just can’t ignore Robots. The essence of it is closing the whole page or any of its part from indexation. Our guide will clarify cases and conditions of using Robots for your websites’ benefit.

Meta tag Robots is used to authorize or prohibit site indexing by search crawlers. The tag provides robots with a possibility to visit all site pages. Moreover, this tag is useful for those who have no access to Robots.txt, but want to set off indexing of files and directories.
Meta Robots tag format
It is placed in the tag of html-document, inside the HEAD. Its format is quite simple (letter case has no value) – META NAME=”ROBOTS” CONTENT=”value.
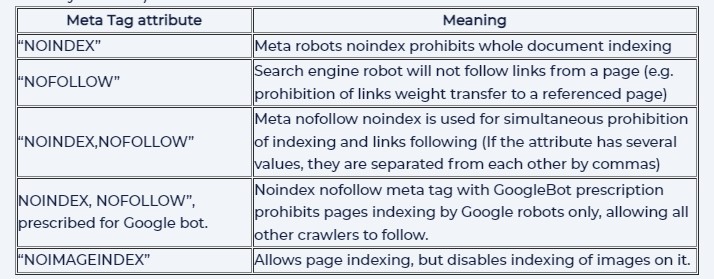
It contains options “(no)index” and “(no)follow “. The Meta robots index, follow are the default values.
Examples of META robots tag
“NOINDEX,NOFOLLOW”Meta nofollow noindex is used for simultaneous prohibition of indexing and links following (If the attribute has several values, they are separated from each other by commas)
Google archives pages snapshot. Cached version allows your end-users to see the page, while the original “specimen” is unavailable (generally, it’s caused by temporary problems of technical character). Cached page appears like it was scanned by Google’s crawler last time. The notification that indicates about cached origin of a page is showed at the page top. Users can access it by clicking on the correspondent button, located on the page of results.
- To prevent all SEs from showing a link, insert “NOARCHIVE” with ROBOTS meta name into the HEAD section.
- To disable the “Cached” link showing only by Google, use “GOOGLEBOT” and “NOARCHIVE” (it only removes the link indexing, while page indexing and its display in search remains).
How to prevent scanning or deleting of page snippets?
A snippet is a descriptive text of a page, placed under the page title, and showed in SERPs.
- To off Google displaying fragments of your page, use “NOSNIPPET”. Note: Cashed pages can be remover together with snippets.
What is no follow and how it can be used to your own benefits?
LinksManagement often faces a situation when new webmasters, bloggers and site owners have troubles with “nofollow”. Ignorance of the obvious things can cost you a lot…

To prevent confusion, we should start with informing you about the fact that html rel nofollow is used for two relatively different purposes in web-documents:
- TThe first case is when meta tag ROBOTS (don’t mix it with txt, as they are two completely different issues) used inside CONTENT attribute.
- The second is when nofollow is used into a tag, and refers to a specific link.
Nofollow is a special attribute of the hyperlink, which prohibits SE to index this link. With the introduction of rel=”nofollow” to a standard form like a href=”site address” link text /a, a site indexing becomes impossible, and the hyperlink takes the form of a href=” site address rel=”nofollow” link text/a.
In fact, link rel=”nofollow” hides only a separate link from the crawler. However, nofollow could also be used the Robots meta tag option to prohibit indexing of a whole page.
A bit of history
Earlier, nofollow was used at the level of a page to show SE that it shouldn’t follow links on this page (i.e. scan the corresponding URL). Before nofollow became possible to individual links, it had required special measures to prevent robots to go by links on the page (e.g., URL of such links was blocked by robots.txt). But finally, the “rel” was standardized, and webmasters got some relief when managing the scanning process.
How does Google deal with forbidden for transition links?
Generally, the transition is not performed. Google does not share any PageRank or link text that could be taken from these links. However, relevant landing pages can still be included into Google index, if other sites refer to them without using nofollow, and if their URLs are provided with a help of Sitemap file.
Widespread rel nofollow examples
- Bad-quality content (e.g. placed in comments). Insert rel=”nofollow” into the tags of such links to reduce the amount of spam and eliminate the unintentional transfer of PageRank to unscrupulous users. In particular, spammers can leave your site alone, if they see that you add “nofollow” to all unconfirmed links. Finally, if you’ll need to recognize and encourage the best authors, you can remove “nofollow” out of correspondent links.
- Paid backlinks. A site position in Google search is partly based on analysis of other sites, referring to it. We recommend you to use nofollow to exclude the value of a site links to its search position. The regulations of search engines require users to provide autoreading info for paid links, as consumers should have possibility to distinguish commercial materials from informational ones.
- Setting the priorities of scanning. Search engine robots cannot log into your account or register as participants in the forum, so you’re not interested in crawlers’ following links like “Register” or “Login.”

In such cases, nofollow helps to optimize crawlers’ work, providing only the pages you want to be scanned. But still, proper organization of a page (intuitive navigation, user-friendly URLs, etc.) is much more important.
Nofollow and site promotion
Sure, nofollow links can’t directly affect a site position in SERPs. Therefore, you should not pay for such links. To find them, check the source code or use special SEO plugins that can be customized to highlight links with nofollow attribute.
Rel = “canonical” for successful indexing in Google
Today, many webmasters use content management systems, as well as different methods of its distribution. So, the same materials can be placed on pages with different URLs:
- Dynamic URL of the pages, presenting the same products, may be different if they appear in SERPs, or a user opens this section by several times.
- Blog services automatically create multiple URLs in case you put the same message in a few sections.
- Your server shows the same materials in a “www” subdomain and in usual http-addresses.
- Content, desired for distribution across multiple sites, is fully or partially repeated in other domains.

Automated tools greatly simplify working with content, but you have to look for non-trivial solutions for users that come to your site from SERPs.
Link rel canonical clearly indicates duplicates page. Additional address properties and related signals (like quality of inbound link mass) are also transferred from duplicate pages to canonical. Rel = “canonical” attribute is supported by all leading SEs.
However, the use of the attribute sometimes causes certain difficulties, which leads to mistakes that can affect pages display in SERPs. To avoid common errors, Google specialists recommend to adhere to the following general rules when introducing rel = “canonical” attribute:
- Most of the duplicate pages must contain links to the canonical address.
- Page that is referred to canonical by rel = “canonical” should exist and have correct URL. Check if a server returns a 404 error.
- Canonical page shouldn’t be closed from indexing.
- Define what page you want to present in and set it as the canonical one. E.g. if a site contains a collection of pages with the same model of goods, with the difference in only color, specify the page with the most popular color as a canonical one.
- Put “canonical” in HTML code.
- Avoid using “canonical” more than once for a single page. Otherwise, search engines simply ignore the attribute designation.
5 typical mistakes when using rel = “canonical”
- It is used for the first pagination page.
- Absolute references are recorded as relative. Certainly, “canonical” can be used both for absolute and relative references, but Google recommends using absolute links to minimize potential errors. If the document contains a basic link, then all relative links will be based on it. However, in cases when absolute reference to a canonical page is recorded as a relative, algorithms can ignore the canonical nature of a page.
- Few pages with the same content are marked as canonical, or the attribute is used by mistake. Google specialists often observe the following situation: webmaster copies a page template, forgetting to change the value of the attribute. If you use templates, don’t forget to check if “canonical” was accidentally copied.
- One of landing page categories is referred to a featured article. In this case, only the page with an article will be indexed.
- It is used in a document body.
Robots meta tag vs robots.txt file
The use of the Robots tag can give you substantial advantages. It can be put to every single page; it has index/noindex and follow/nofollow options.

Here are examples when Meta tag robots really rocks:
- Non-unique content. Not necessarily, it should be a copy-paste or stolen content, it may also be official documents, laws. You can disable indexing the whole amount of these pages, or just particularly (prohibiting only content indexing).
- Publication of excessive number of links on the page. If you want to share interesting links, but not to compromise yourself in eyes of search engines in a way of publishing an excessive number of backlinks, then you can disable page indexing, while it will be available to your visitors.
- Archives, headings and labels create duplicate content. But they contain references to our own pages, and these references can participate in internal linking, transferring weight to the homepage, articles pages and others. Thus, using the Robots you can tell Google not to index the content (as it creates doubles) of the pages, but to pass by links on these pages. In this way you’ll save internal linking and create an additional tool to increase the static weight of the site pages.
Meta robots WordPress plugins
As we know, there’s no short way to add meta Robots tag to a WP pages. Sure, if you’re not using special plugins.
- Robots Meta Plugin by Yoast. The advantages:
- Easily adding of (no)follow, no(index) options to open/close indexing.
- Option out DMOZ and Yahoo! Directory descriptions by noodp an noydir meta robots tags.
- Disabling of date-based and author archives.
- Nofollow tag and outbound links.
- Add Robots meta tag to separate pages and posts.
- Site verifying with Yahoo! Site Explorer and GWT.
- Easy installation: just download the plugin, copy it to correspondent directory of your site, enable in admin panel and configure as you want.
Online Robots meta tag generator. A simple online instrument by using which you can check the correctness of the tag, choose options you want and copy result to clipboard.
Summing up
For any SE it does not matter the way you specify the commands for indexing – by using robots.txt or meta robots tag. The main thing is not to set conflicting opposite commands. E.g. if you close page for indexing in robots.txt, and manually set up meta robots follow tag option, then a crawler will take into account a command with a higher priority which is always “noindex”. So be careful when using both variants of Robots on a site. Read more about optioning of robots.txt in our next article.
Related Posts

Last updated Jan 17, 2023 | Published Oct 15, 2015

Published Jul 11, 2023

Last updated Aug 24, 2022 | Published Nov 23, 2021

Last updated Apr 25, 2022 | Published Apr 21, 2015

Last updated Mar 31, 2022 | Published May 25, 2021

Last updated Mar 27, 2024 | Published Jul 21, 2015
Enter URL & See What We Can Do Submit the form to get a detailed report, based on the comprehensive seo analysis.